Genai
Serving Stable Diffusion
Discover how to effortlessly deploy your fine-tuned Stable Diffusion model using Ray Serve for scalable and production-grade serving.
Serving Dreambooth with Ray Serve
This notebook will guide you through the process of deploying and managing your fine-tuned Stable Diffusion model using Ray Serve. Ray Serve is a powerful framework designed for scalable serving, and it eases the transition from development to production-grade deployment.
Table of Contents
- Introduction to Ray Serve
- Key components
- How to Create a Basic Service
- Hello world!
- Deploying Dreambooth
- Defining deployments
- Resource management and autoscaling
- Binding deployments
- Running Ray Serve
- Defining deployments
- Making Requests to the Endpoint
1. Introduction to Ray Serve
Ray Serve is a framework for serving machine learning systems. With features like autoscaling, services composition, and response streaming, it offers efficient, high-performance serving for Large Language Model and Generative AI applications.
Built on top of Ray, it abstracts away the infrastructure complexities while inheriting the performance capabilities of the core distributed runtime. As a Ray AI Library, Serve extends the workflow from Ray Data, Train, and Tune to provide a cohesive end-to-end development to production experience.
Key Components
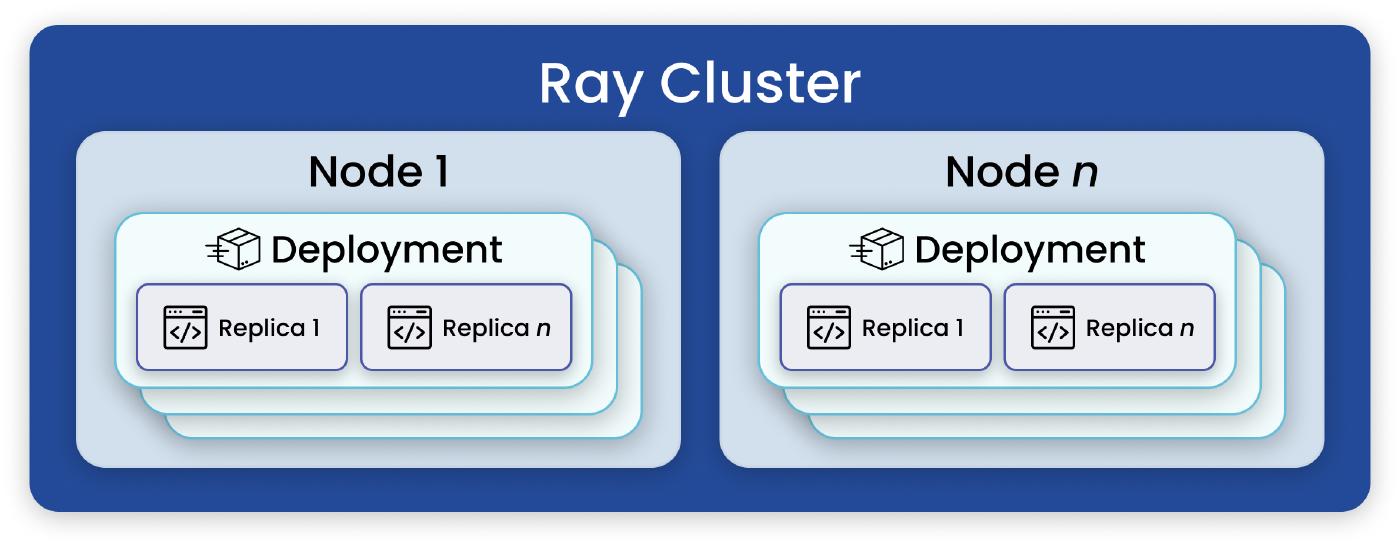
Deployment: A deployment is the fundamental user-facing unit in Ray Serve. Within a deployment are a number of replicas, which are copies of a class or function started in separate Ray Actors, and during runtime, these replicas can be autoscaled to match request traffic.
a. Ingress Deployment (HTTP Handling): The ingress deployment serves as the entry point for all traffic. It defines the HTTP handling logic for the application, with the
__call__method of the class handling incoming requests. Serve also integrates with FastAPI for expressive API definitions.ServeHandle (Composing Deployments): A ServeHandle is a bound deployment and allows multiple independent deployments to call into each other. In this way, it facilitates flexible and complex model composition where bound deployments can reference other bound deployments. At runtime, these references become ServeHandles for querying.
Application: An application is composed of one or more deployments and can be accessed via HTTP routes or Python handles.
2. How to Create a Basic Service
import ray
from ray import serve# Define a deployment by using `serve.deployment` decorator on a Python class or function.
@serve.deployment
class MyFirstDeployment:
# Take the message to return as an argument to the constructor.
def __init__(self, msg):
self.msg = msg
def __call__(self):
return self.msg# The `.bind()` method binds the deployment with the arguments to the constructor.
# This returns a `ServeHandle` that can be passed to other deployments or used to start a service.
my_first_deployment = MyFirstDeployment.bind("Hello world!")
# Start a service.
handle = serve.run(my_first_deployment)print(ray.get(handle.remote())) # "Hello world!"serve.shutdown() # Deletes all applications and shuts down Serve system actors.3. Deploying Dreambooth
Let’s now move beyond a basic service and deploy our fine-tuned model from the previous notebook. We’ll follow the same pattern as the “Hello world!” example, but use Serve’s intergration with FastAPI for more expressive HTTP handling.
Using deployments and binding mechanisms allows you to define complex web service architectures where classes can communicate with each other, and are exposed through HTTP endpoints. Ray Serve manages the deployment, scaling, and routing of these microservices, enabling efficient and scalable serving for machine learning applications.
import torch
from diffusers import DiffusionPipeline
from fastapi import FastAPI
from fastapi.responses import Response
from io import BytesIO# This is the same fine-tuned model you just created in the previous notebook.
fine_tuned_model_path = "/mnt/cluster_storage/fine-tuned-model"Define a StableDiffusion class for Serve deployment
The @serve.deployment decorator is used to define a deployable unit for Ray Serve. When applied to a class, this decorator specifices that instances of this class can be deployed as microservices that can be accessed through HTTP requests.
@serve.deployment(
autoscaling_config={
'min_replicas': 0,
'initial_replicas': 1,
'max_replicas': 2 # We have 2 GPUs available.
},
ray_actor_options={"num_gpus": 1}, # Each replica should have access to 1 GPU
)
class StableDiffusion:
def __init__(self):
# Load the DiffusionPipeline model from the fine-tuned model path
self.pipeline = DiffusionPipeline.from_pretrained(
fine_tuned_model_path, torch_dtype=torch.float16
)
self.pipeline.set_progress_bar_config(disable=True)
self.pipeline.to("cuda") # Ray will let us guarantee a GPU is available.
# Generate images for each prompt.
def generate(self, prompt: str, img_size: int = 512):
return self.pipeline(prompt, height=img_size, width=img_size).images[0]Replicas and autoscaling
In Ray’s Serve, you can manage resources and enable autoscaling for your deployments using the ray_actor_options parameter and related decorators.
Resources like num_cpus, num_gpus, and custom resources can be specified for each deployment using the ray_actor_options parameter which allows Ray to efficiently allocate code to suitable nodes in a heterogeneous cluster.:
@serve.deployment(ray_actor_options={'num_cpus': 2, 'num_gpus': 2, 'resources': {"my_accelerator": 1}})
class Demo:
...More details: Resource Management in Ray Serve
Deployments can have individual resource management and autoscaling configurations:
- For a fixed number of replicas, use
num_replicas:
@serve.deployment(num_replicas=3)- For autoscaling, use
autoscaling_configwith various options:
@serve.deployment(
autoscaling_config={
'min_replicas': 1,
'initial_replicas': 2,
'max_replicas': 5,
'target_ongoing_requests_per_replica': 10,
}
)You can even set min_replicas to zero for a “serverless” design, which doesn’t reserve resources during startup.
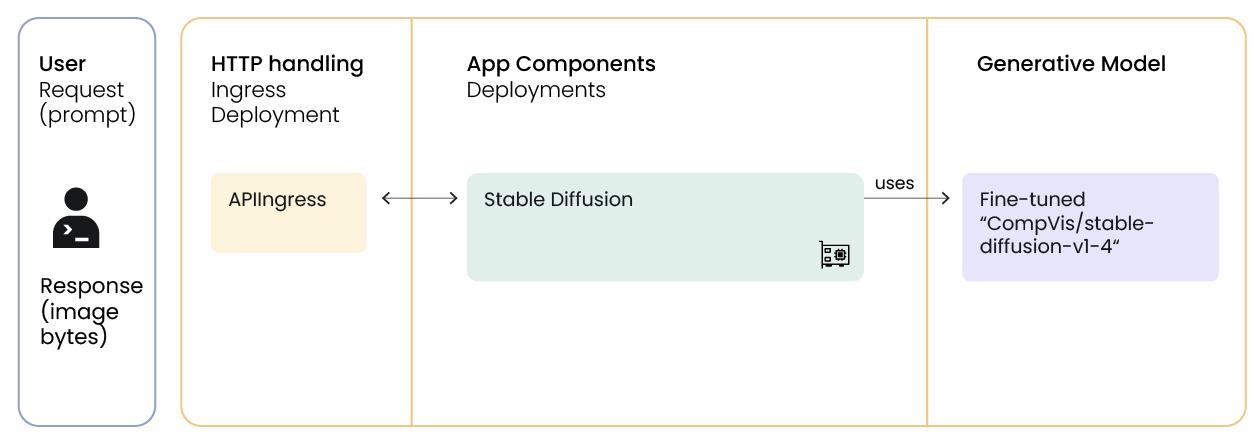
Define the APIIngress Serve deployment
Next, we’ll define the actual API endpoint to live at /dreambooth.
The @serve.deployment decorator indicates that instances of this class will be deployable units. Every service needs an entry point, and we specify this with the @serve.ingress(app) decorator. HTTP requests to the FastAPI routes will be directed to methods of the APIIngress class.
# Create a FastAPI application that will be used to define the endpoints for the API.
app = FastAPI()
@serve.deployment(num_replicas=1) # Specify that instances of this class should be deployed by Ray Serve as a microservice with one replica.
@serve.ingress(app) # Indicates that this class will serve as the entry point for incoming requests to the Fast API application;
# Links the FastAPI app to this Ray Serve deployment.
class APIIngress:
def __init__(self, diffusion_model_handle) -> None:
self.handle = diffusion_model_handle
# The `@app.get` tells FastAPI that the function below is in charge of handling requests.
@app.get(
"/dreambooth",
responses={200: {"content": {"image/png": {}}}},
response_class=Response,
)
async def entry(self, prompt: str, img_size: int = 512):
assert len(prompt), "You need to supply a prompt."
# First await the remote object reference, then retrieve the image.
image = await (await self.handle.generate.remote(prompt, img_size=img_size))
file_stream = BytesIO()
image.save(file_stream, "PNG")
return Response(content=file_stream.getvalue(), media_type="image/png")Binding Serve deployments
Now, let’s deploy the Ray Serve application locally at http://localhost:8000/dreambooth.
Here the APIIngress is bound to the StableDiffusion deployment so that incoming requests to the FastAPI routes will be processed by the methods in the APIIngress, and when the generate method is called, it will internally call the generate method of the StableDiffusion instances.
port = 8000
entrypoint = APIIngress.bind(StableDiffusion.bind())
# Shutdown any lingering deployments, if any.
serve.shutdown()Running Ray Serve
This line starts the deployment of both the StableDiffusion and APIIngress classes. The specified entrypoint defines how the request processing flows between these deployments.
serve.run(entrypoint, port=port, name="dreambooth")
print("Done setting up replicas! Now accepting requests...")4. Make Requests to the Endpoint
Next, we’ll build a simple client to submit prompts as HTTP requests to the local endpoint at http://localhost:8000/dreambooth.
import datetime
import os
import requests
from utils import show_imagesendpoint = f"http://localhost:{port}/dreambooth"@ray.remote(num_cpus=0)
def make_request(prompt, image_size):
resp = requests.get(endpoint, params={"prompt": prompt, "img_size": image_size})
return resp.contentnum_images = 4
image_size = 512
num_images_per_prompt = 4
prompt = "photo of unqtkn dog having breakfast"Below, once the Stable Diffusion model finishes generating your image(s), it will be included in the HTTP response body. The client saves all the images in a local directory for you to view, and they’ll also show up in the notebook cell.
images = ray.get([make_request.remote(prompt, image_size) for _ in range(num_images)])# Create a directory with the formatted date and time
current_datetime = datetime.datetime.now()
serve_images_dir = current_datetime.strftime("%Y-%m-%d_%H-%M-%S")
os.makedirs(serve_images_dir)
# Save images
filenames = []
for i, image in enumerate(images):
filename = os.path.join(serve_images_dir, f"{i}.png")
with open(filename, "wb") as f:
f.write(image)
filenames.append(filename)
show_images(filenames)# Shut down the model replicas once you're done!
serve.shutdown()Exercise
Try to change the
autoscaling_configdefined in the Stable Diffusion deployment to further specify resource management. You can:
- Specify the number of CPUs, GPUs, and custom resources.
- Fix the number of replicas.
- Check out Resource Management in Ray Serve for more details.
After each change, go to the Ray Dashboard to see active Serve deployments.
Exercise
We can compose multiple deployments together. You already experimented with this by binding an
Ingressdeployment with theStableDiffusiondeployment. See if you can add in another deployment. Some ideas include:
- Add in a filter that screens out grayscale and/or censored images.
- Prompt engineer before the image gets generated to encourage a diversity of results.
- Use the base model for prompts unrelated to the subject matter and the fine-tuned model for unique subject matter prompts.