Llms
Retrieval Augmented Generation
Design a large-scale architecture for retrieval-augmented generation (RAG) applications with the an Embedder, Vector database, Prompt builder, Chat or LLM wrapper, Orchestrator, and Ingress.
! pip install chromadb==0.4.6import json
import requests
from InstructorEmbedding import INSTRUCTOR
from ray import serve
from starlette.requests import RequestLarge scale architecture for retrieval-augmented generation (RAG) applications
Roadmap to architecture for large-scale RAG apps
- Goals and requirements for production systems
- Key components of a basic scalable app
- Core features and next steps for each component
- Running it end-to-end
In a large-scale design and deployment, we want to address several operational, performance, and cost goals:
- the overall system should be scalable to the limit of our budget and available hardware
- each component should be scalable separately, including “serverless,” manual, and autoscaling
- our deployment mechanism should support fractional resource usage so that we can most efficiently use GPUs and other hardware
- it should be possible to leverage tight packing or sparse spreading for component replicas, depending on their compute, I/O, and data needs
- we would like to avoid manual placement of resources
- the system should support high availability and load balancing throughout all calls to various components
- it should be straightforward to code, modify, configure, and upgrade components
Ray and Ray Serve – on top of a resource manager like Anyscale or KubeRay+Kubernetes – provides an elegant platform to meet these requirements.
We can structure a basic system as a collection of Serve deployments, including at least one ingress deployment – it might look like this:
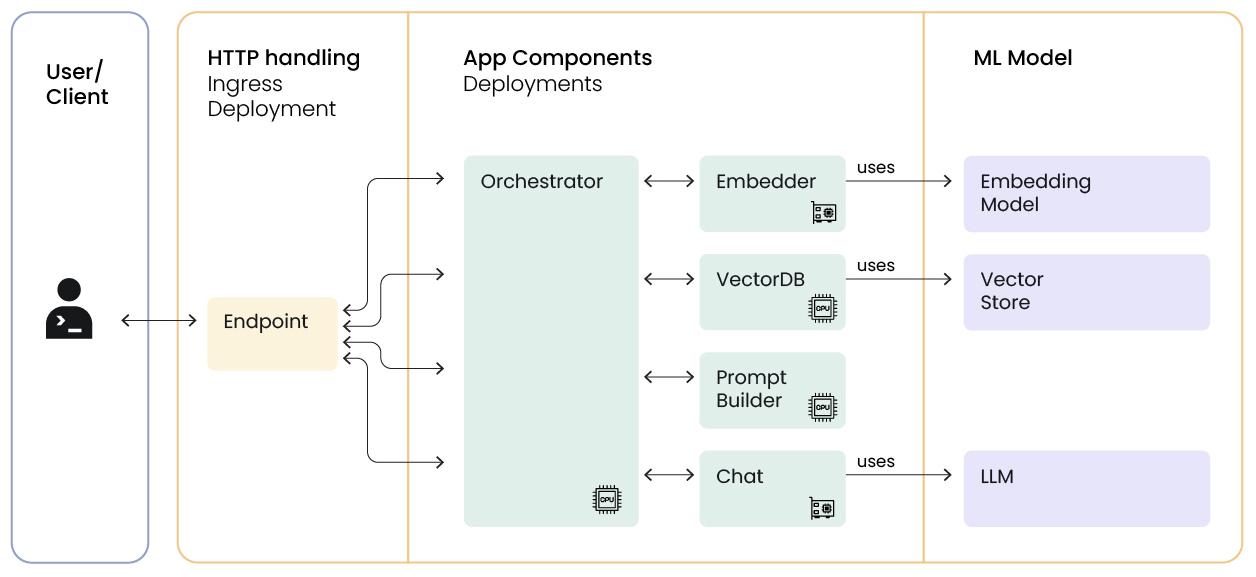
The key components are
- Embedder for creating embedding vectors of queries and data
- Vector database for retrieving semantically relevant information
- Prompt builder for creating custom prompts based on queries, supporting information, and task (goal)
- Chat or LLM wrapper for collecting and dispatching inference (sampling) calls to the language model(s)
- Orchestrator to manage the flow of data through the various components
- Ingress to handle HTTP calls, streaming responses, and data conversion
EMBEDDER_MODEL = 'hkunlp/instructor-large'
CHAT_MODEL = 'stabilityai/StableBeluga-7B'We’ll code and run a skeletal implementation of this architecture.
- To deploy at a larger scale, we would want to provision more resources and allow larger scaling
- We would also want to enable capabilities like batching, since most language models generate much better throughput via batched inference
For each component below, we’ll also note specific additional capabilities to consider as “next steps” in evolving this application toward production
Embedder
This embedder component encodes only one string (to one vector) at a time.
We may want to extend this capability to encode batches of vectors for
- batched inference tasks
- generation of new knowledge bases or expansion of our existing knowledge base (see database component below)
@serve.deployment(ray_actor_options={"num_gpus": 0.1}, autoscaling_config={ "min_replicas": 1, "max_replicas": 2 })
class Embedder:
def __init__(self, model: str):
self._model = INSTRUCTOR(model, cache_folder="/mnt/local_storage")
def get_response(self, message):
return self._model.encode(message).tolist()
embedder = Embedder.bind(EMBEDDER_MODEL)Database
This database component scales out effectively given a static vector dataset.
We likely want to add some support for different types of indexes as well as retrieving stats. Future steps include an architecture for adding and/or updating and re-indexing the dataset.
The pattern employed will depend on concrete decisions regarding how often and how large the updates will be
- scaling the “write path” on the database typically requires some design balance between speed, consistency, and availability
- while a small number vector databases currently support some form of scale-out on the write path, none are very simple, and the segment is evolving quickly – so we expect to see new options soon
- cloud vector store services may or may not be a suitable solution
@serve.deployment(autoscaling_config={ "min_replicas": 4, "max_replicas": 8 },
ray_actor_options={ "runtime_env" : { "pip": ["chromadb"] }})
class ChromaDBReader:
def __init__(self, collection: str):
self._collection_name = collection
self._coll = None
def get_response(self, query_vec):
if self._coll is None:
import chromadb
chroma_client = chromadb.PersistentClient(path="/mnt/cluster_storage/vector_store")
self._coll = chroma_client.get_collection(self._collection_name)
return self._coll.query(query_embeddings=[query_vec], n_results=3,)['documents'][0]
db = ChromaDBReader.bind('persistent_text_chunks')Prompt generation
This example prompt generation component supports a single templated prompt styled for a small number of LLMs (the ### User / ### Assistent pattern is specific to certain models).
We may want to expand this service to support
- multiple tasks/goals with specific prompt templates or patterns
- multiple models with different mechanisms for specifying system vs. user prompt
- use cases which require altering the system prompt
- requiring JSON, SQL, Python, or other output types
- constrained generation (applying a schema, regex, or other specification to guide generation; e.g., via https://github.com/normal-computing/outlines)
It may become useful to back the prompt generator with a database, templating scheme, or other content-management tools.
It is also important to consider the risk of prompt injection and consider other security measures which may be useful in prompting
base_prompt = """You are a helpful assistant who can answer questions about a text based on your existing knowledge and documents supplied here.
When answering questions, use the following relevant excerpts from the text:
{ newline.join([doc for doc in docs]) }
If you don't have information to answer a question, please say you don't know. Don't make up an answer.### User: """
@serve.deployment(autoscaling_config={ "min_replicas": 1, "max_replicas": 4 })
class PromptBuilder:
def __init__(self, base_prompt):
self._base_prompt = base_prompt
def get_response(self, query, docs):
newline = '\n'
return eval(f'f"""{self._base_prompt}"""') + query + '\n\n### Assistant:\n'
prompt_builder = PromptBuilder.bind(base_prompt)Chat component
Below are simple examples of a chat service wrapping a single huggingface-hosted model as well as a similar service featuring acceleration with vLLM.
Natural extensions of this pattern include
- multiple models (e.g., different models for different tasks)
- mixture-of-experts and/or generator-critic ensembles
Also important to consider are
- batching I/O (the below examples “implicitly” support batching in the
messagesparam, but we may want to make that more explicit - streaming response
- and potentially streamed batching
Non-accelerated chat
@serve.deployment(ray_actor_options={"num_gpus": 0.9}, autoscaling_config={ "min_replicas": 1, "max_replicas": 2 })
class Chat:
def __init__(self, model: str):
self._model = None
self._model_name = model
def get_response(self, message) -> str:
if self._model is None:
import torch
from transformers import pipeline
self._model = pipeline("text-generation", model=self._model_name, model_kwargs={
'torch_dtype':torch.float16,
'device_map':'auto',
"cache_dir": "/mnt/local_storage"})
return self._model(message, max_length=1500)[0]['generated_text'].split('### Assistant:\n')[1]
chat = Chat.bind(model=CHAT_MODEL)Accelerated chat with vLLM
@serve.deployment(ray_actor_options={"num_gpus": 0.9}, autoscaling_config={ "min_replicas": 1, "max_replicas": 2 })
class AcceleratedChat:
def __init__(self, model: str):
from vllm import LLM, SamplingParams
self._llm = LLM(model=model, download_dir='/mnt/local_storage')
self._sp = SamplingParams(max_tokens=200)
def get_response(self, message) -> str:
return self._llm.generate(message, sampling_params = self._sp)[0].outputs[0].text
vllm_chat = AcceleratedChat.bind(model=CHAT_MODEL)Orchestration
An orchestration service allows us to link the various components while maintaining separation of concerns.
This simple orchestrator follows a “chain” pattern and implicitly assumes certain component interfaces.
We might extend this orchestrator by
- allowing additional control flows
- creating a generic dict- and/or ndarry- based API for all component I/O
@serve.deployment(autoscaling_config={ "min_replicas": 1, "max_replicas": 4 })
class Orchestrator:
def __init__(self, embedder, db, prompt_builder, chat):
self._embedder = embedder
self._db = db
self._prompt_builder = prompt_builder
self._chat = chat
async def get_response(self, query):
embed = self._embedder.get_response.remote(query)
docs = self._db.get_response.remote(await embed)
prompt = self._prompt_builder.get_response.remote(query, await docs)
resp = self._chat.get_response.remote(await prompt)
ref = await resp # collecting async response (Ray ObjectRef) from chat call
result = await ref # collecting Python string from Ray ObjectRef
return result
orchestrator = Orchestrator.bind(embedder, db, prompt_builder, chat) # can swap in vllm_chat hereIngress deployment (HTTP interface)
Natural extensions of this interface include
- accommodating streaming responses
- handling multimodal I/O; e.g., HTTP upload/download semantics for images
- adding escaping/checking to reduce risk of injection and other content-based exploits
@serve.deployment
class Ingress:
def __init__(self, orchestrator):
self._orchestrator = orchestrator
async def __call__(self, request: Request) -> dict:
data = await request.json()
data = json.loads(data)
result = await self._orchestrator.get_response.remote(data['input'])
output = await result
return {"result": output }
ingress = Ingress.bind(orchestrator)Despite the skeletal implementations here, we can see the full modular architecture in action
app = serve.run(ingress, name='e2e')def talk_to_LLM(query):
result = requests.post("http://localhost:8000/", json = json.dumps({ 'input' : query})).json()
return result['result']talk_to_LLM("Describe the body of water in Utah")talk_to_LLM("Tell me as much as you can about the robbery")talk_to_LLM("Did Phileas Fogg really rob the bank?")serve.delete('e2e')serve.shutdown()