Ray-ai-libraries
Quick End-to-end Example
Get introduced to the Ray AI Libraries in this overview. These libraries are built on top of Ray Core and provide a unified framework for machine learning tasks with a focus on performance and scalability.
0. Introduction to the Ray AI Libraries
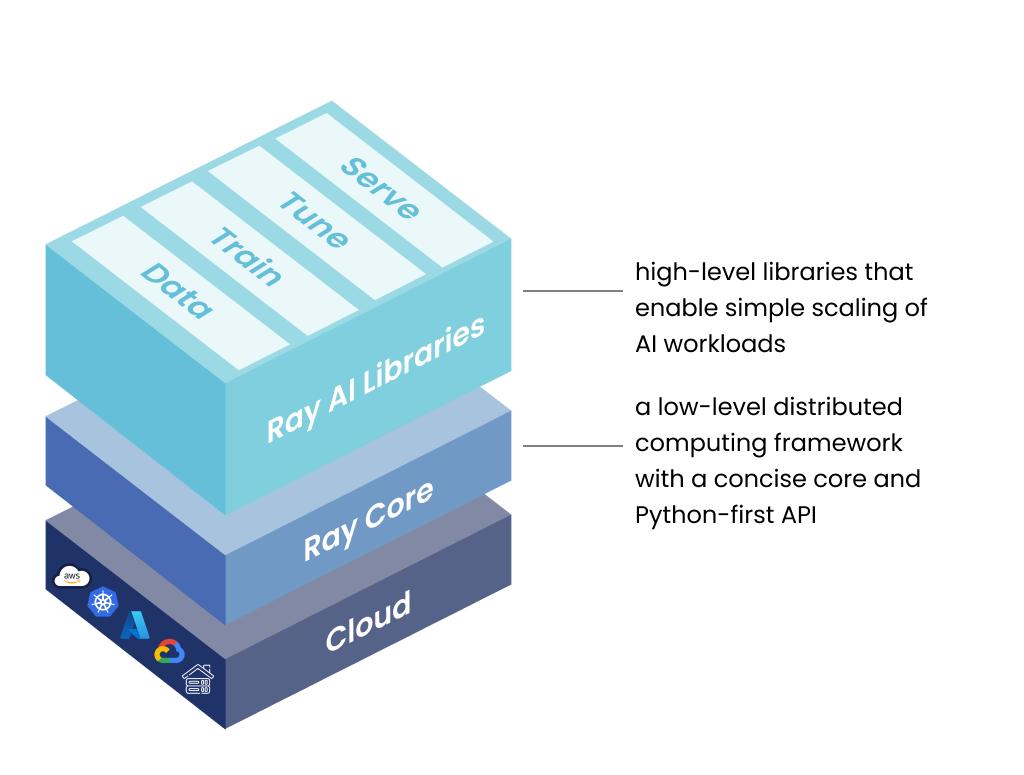
Built on top of Ray Core, the Ray AI Libraries inherit all the performance and scalability benefits offered by Core while providing a convenient abstraction layer for machine learning. These Python-first native libraries allow ML practitioners to distribute individual workloads, end-to-end applications, and build custom use cases in a unified framework.
The Ray AI Libraries bring together an ever-growing ecosystem of integrations with popular machine learning frameworks to create a common interface for development.
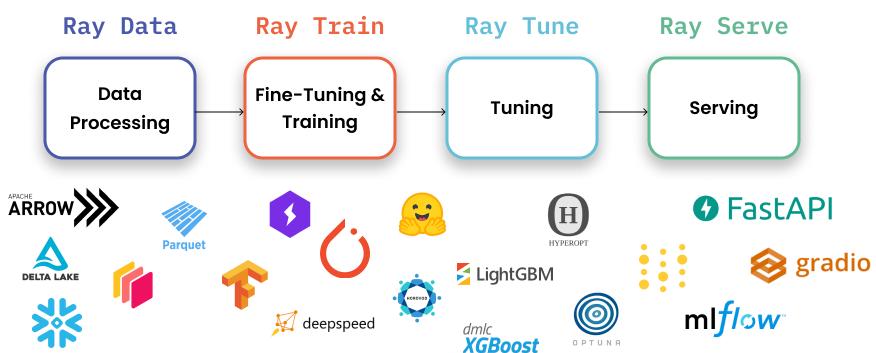
Table of Contents
- Ray Data
- Scalable, framework-agnostic data loading and transformation across training, tuning, and inference.
- Ray Train
- Distributed multi-node and multi-core training with fault tolerance that integrates with popular machine learning libraries.
- Ray Tune
- Scales hyperparameter tuning to optimize model performance.
- Ray Serve
- Deploys a model or ensemble of models for online inference.
Quick end-to-end example
| Ray AIR Component | NYC Taxi Use Case |
|---|---|
| Ray Data | Ingest and transform raw data; perform batch inference by mapping the checkpointed model to batches of data. |
| Ray Train | Use Trainer to scale XGBoost model training. |
| Ray Tune | Use Tuner for hyperparameter search. |
| Ray Serve | Deploy the model for online inference. |
For this classification task, you will apply a simple XGBoost (a gradient boosted trees framework) model to the June 2021 New York City Taxi & Limousine Commission’s Trip Record Data. This dataset contains over 2 million samples of yellow cab rides, and the goal is to predict whether a trip will result in a tip greater than 20% or not.
Dataset features
passenger_count- Float (whole number) representing number of passengers.
trip_distance- Float representing trip distance in miles.
fare_amount- Float representing total price including tax, tip, fees, etc.
trip_duration- Integer representing seconds elapsed.
hour- Hour that the trip started.
- Integer in the range
[0, 23]
day_of_week- Integer in the range
[1, 7].
- Integer in the range
is_big_tip- Whether the tip amount was greater than 20%.
- Boolean
[True, False].
import ray
from ray.train import ScalingConfig, RunConfig
from ray.train.xgboost import XGBoostTrainer
from ray.train.xgboost import XGBoostPredictor
from ray import tune
from ray.tune import Tuner, TuneConfig
from ray import serve
from starlette.requests import Request
import requests, json
import numpy as npRead, preprocess with Ray Data
ray.init()dataset = ray.data.read_parquet("s3://anonymous@anyscale-training-data/intro-to-ray-air/nyc_taxi_2021.parquet").repartition(16)
train_dataset, valid_dataset = dataset.train_test_split(test_size=0.3)Fit model with Ray Train
trainer = XGBoostTrainer(
label_column="is_big_tip",
scaling_config=ScalingConfig(num_workers=4, use_gpu=False),
params={ "objective": "binary:logistic", },
datasets={"train": train_dataset, "valid": valid_dataset},
run_config=RunConfig(storage_path='/mnt/cluster_storage/')
)
result = trainer.fit()Optimize hyperparameters with Ray Tune
tuner = Tuner(trainer,
param_space={'params' : {'max_depth': tune.randint(2, 12)}},
tune_config=TuneConfig(num_samples=3, metric='train-logloss', mode='min'),
run_config=RunConfig(storage_path='/mnt/cluster_storage/'))
checkpoint = tuner.fit().get_best_result().checkpointBatch inference with Ray Data
class OfflinePredictor:
def __init__(self):
import xgboost
self._model = xgboost.Booster()
self._model.load_model(checkpoint.path + '/model.json')
def __call__(self, batch):
import xgboost
import pandas as pd
dmatrix = xgboost.DMatrix(pd.DataFrame(batch))
outputs = self._model.predict(dmatrix)
return {"prediction": outputs}predicted_probabilities = valid_dataset.drop_columns(['is_big_tip']).map_batches(OfflinePredictor, compute=ray.data.ActorPoolStrategy(size=2))predicted_probabilities.take_batch()Online prediction with Ray Serve
@serve.deployment
class OnlinePredictor:
def __init__(self, checkpoint):
import xgboost
self._model = xgboost.Booster()
self._model.load_model(checkpoint.path + '/model.json')
async def __call__(self, request: Request) -> dict:
data = await request.json()
data = json.loads(data)
return {"prediction": self.get_response(data) }
def get_response(self, data):
import pandas as pd
import xgboost
dmatrix = xgboost.DMatrix(pd.DataFrame(data, index=[0]))
return self._model.predict(dmatrix)
handle = serve.run(OnlinePredictor.bind(checkpoint=checkpoint))sample_input = valid_dataset.take(1)[0]
del(sample_input['is_big_tip'])
del(sample_input['__index_level_0__'])
requests.post("http://localhost:8000/", json=json.dumps(sample_input)).json()serve.shutdown()