Ray-serve
Building Services with Ray Serve
Create deployments with specific resource requirements, connect or compose deployments, and specify runtime environments for specific deployments, including GPU utilization for tasks.
import ray
from ray import serve
import requests, json
from starlette.requests import Request
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSeq2SeqLMBuilding Applications with Ray Serve
Roadmap to building applications
- Create deployments which require specific resources (e.g., GPUs)
- Understand how to connect (compose) deployments
- Specify runtime environments for specific deployments, if needed
Specifying service resources
Resources can be specified on a per-deployment basis and, if we want, in fractional units, via the ray_actor_options parameter on the @serve.deployment decorator.
As a realistic example, we can upgrade the “hello world” chatbot to use a Huggingface LLM employing GPU resources.
@serve.deployment(ray_actor_options={'num_gpus': 0.5})
class Chat:
def __init__(self, model: str):
# configure stateful elements of our service such as loading a model
self._tokenizer = AutoTokenizer.from_pretrained(model)
self._model = AutoModelForSeq2SeqLM.from_pretrained(model).to(0)
async def __call__(self, request: Request) -> dict:
# path to handle HTTP requests
data = await request.json()
data = json.loads(data)
# after decoding the payload, we delegate to get_response for logic
return {'response': self.get_response(data['user_input'], data['history']) }
def get_response(self, user_input: str, history: list[str]) -> str:
# this method receives calls directly (from Python) or from __call__ (from HTTP)
history.append(user_input)
# the history is client-side state and will be a list of raw strings;
# for the default config of the model and tokenizer, history should be joined with '</s><s>'
inputs = self._tokenizer('</s><s>'.join(history), return_tensors='pt').to(0)
reply_ids = self._model.generate(**inputs, max_new_tokens=500)
response = self._tokenizer.batch_decode(reply_ids.cpu(), skip_special_tokens=True)[0]
return responseResources can include
num_cpusnum_gpusresourcesdictionary containing custom resources- custom resources are tracked and accounted as symbols (or tags) in order to match actors to workers
Example
@serve.deployment(ray_actor_options={'num_cpus' : 2, 'num_gpus' : 2, resources : {"my_super_accelerator": 1}})
class Demo:
...The purpose of the declarative resource mechanism is to allow Ray to place code on suitable nodes in a heterogeneous cluster without our having know which nodes have which resources to where our code should run.
Best practice: if some nodes have a distinguising feature, mark and request it as a resource, rather than trying to determine which nodes are present and where your code will run.
For more details, see https://docs.ray.io/en/releases-2.6.1/serve/scaling-and-resource-allocation.html#resource-management-cpus-gpus
chat = Chat.bind(model='facebook/blenderbot-400M-distill')
handle = serve.run(chat, name='basic_chat')This deployment handles both HTTP ingress and model inference – we’ll separate those in subsequent improvements.
Since the current example serves as an ingress deployment, we can call it via HTTP
sample_json = '{ "user_input" : "hello", "history" : [] }'
requests.post("http://localhost:8000/", json = sample_json).json()To make it faster and simpler to experiment and iterate, we’ll use the ServeHandle to directly call methods instead.
message = 'My friends are cool but they eat too many carbs.'
history = []
response_handle = handle.get_response.remote(message, history)
response = ray.get(response_handle)
responseWe prepare a message and a chat history list and call our chat service via Python
history += [message, response]
historymessage = "I'm not sure."
response_handle = handle.get_response.remote(message, history)
response = ray.get(response_handle)
responseserve.delete('basic_chat')Composing services with Ray for chatbot en Français: roadmap for additional Services
The underlying chatbot model we’ve used only supports English interaction. But we can learn more about serve while adding French language support.
Roadmap to English & French chat
- Implement a translation service between French and English
- Implement a language detection service
- Implement a routing (dispatch) service:
- If the incoming prompt is French, then
- Route the inbound prompt through the FR-EN translator
- Pass the EN prompt to the chat model
- Pass the EN output from the chat model through the EN-FR translator
- Return the French response
- Otherwise (if the prompt is in English), pass it straight to the chatbot as we did earlier and return the (English) response
- If the incoming prompt is French, then
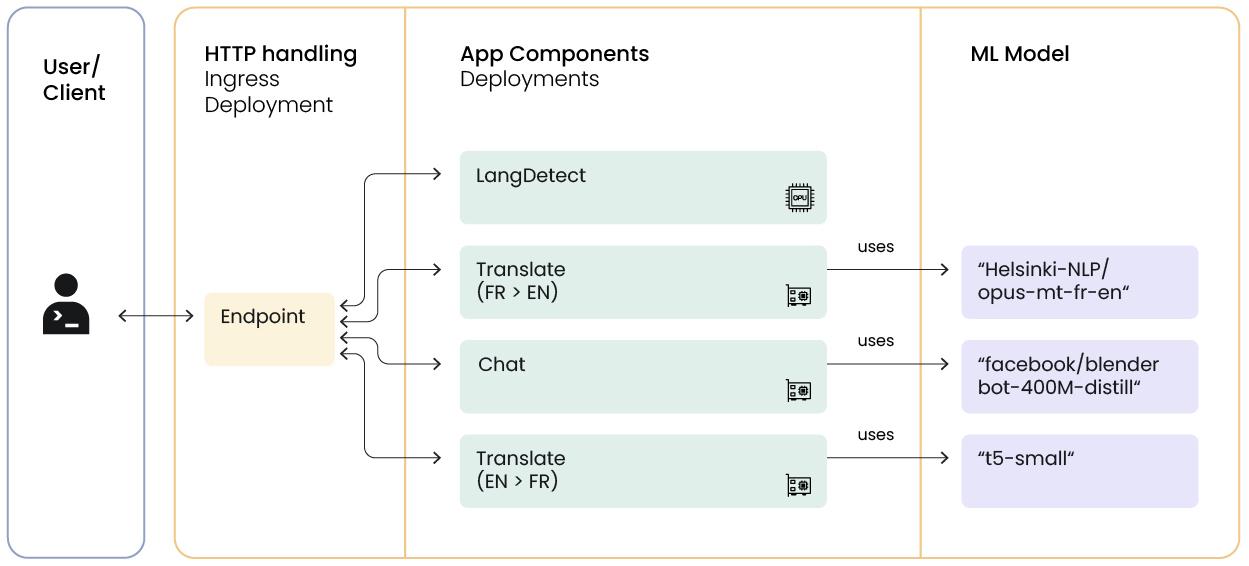
Let’s look using Ray Serve to implement model inference with these composed and conditional-flow elements using Python method calls (https://docs.ray.io/en/releases-2.6.1/serve/key-concepts.html#servehandle-composing-deployments). Later we’ll look at an alternative approach using Ray’s Deployment Graph API.
We’ll implement parts 1 and 2 first…
Translation service
Runtime environments
We have many options for managing dependencies – e.g., Python libraries and versions, resource file, etc.
Dependencies can be provided at the level of Node/VM/container, Ray jobs, actors, tasks, and more.
With Ray Serve, we can optionally specify environment requirements at the Deployment level, and Ray will ensure that the specified environment is available to that deployment.
In the following example, we’ll create
- some services that use libraries available in our general Ray enviornment
- a service that requires a specific Python library (a language detector library) to illustrate the environment feature
Since we are discussing dependencies, its important to remember that it’s a good practice to keep as many dependencies as possible in our general Ray worker environments, and to import them as usual.
Just because we can create lots of custom environments in our code doesn’t mean we should
In this first service, we import pipeline from Huggingface transformers. Later, the specific pipeline we need will require sentencepiece. We’ll demo installing sentencepiece via the Runtime Environment.
Beyond just specifying the library, we have to be careful about the order of imports and other calls, to ensure we don’t need something from the library before it’s available. We ensure that by delaying imports or use of anything with a relevant import until an actual method is called on our service. We can capture variables as usual in the constructor.
runtime_env = {"pip": ["sentencepiece==0.1.99"]}@serve.deployment(ray_actor_options={"runtime_env" : runtime_env})
class Translate:
def __init__(self, task: str, model: str):
self._task = task
self._model = model
self._pipeline = None
def get_response(self, user_input: str) -> str:
if (self._pipeline is None):
self._pipeline = pipeline(task=self._task, model=self._model)
outputs = self._pipeline(user_input)
response = outputs[0]['translation_text']
return response
translate_en_fr = Translate.bind(task='translation_en_to_fr', model='t5-small')
translate_fr_en = Translate.bind(task='translation_fr_to_en', model='Helsinki-NLP/opus-mt-fr-en')Notice how we have two different services but they are built on the same reusable code by calling .bind() with different initialization parameters.
We don’t need to define new deployments for every service we use.
This time we’re haven’t published an application (via serve.run()) because these components will be invoked only by our main service deployment.
Language detection
We can create the language detection service in a similar way.
This service is lighter weight because we’re using https://github.com/pemistahl/lingua-py … which leverages traditional NLP and n-grams for detection instead of a deep learning model. It can handle more traffic than, e.g., the chat model – and it won’t require a GPU. So we can benefit from Ray Serve’s fine-grained resource allocation.
Lingua is optimized for strong detection on very short text snippets, like tweets, so it should be useful for our chat exchanges.
In this service implementation, we’ll demonstrate the custom environment feature by requiring a pip install of lingua-language-detector wherever this deployment happens to run. Ray will ensure this environment is installed as needed. But note the import is deferred until the get_response(...) method is called.
@serve.deployment(ray_actor_options={"runtime_env" : {"pip": ["lingua-language-detector==1.3.2"]}})
class LangDetect:
def __init__(self):
self._detector = None
def get_response(self, user_input: str) -> str:
from lingua import Language, LanguageDetectorBuilder
if (self._detector is None):
languages = [Language.ENGLISH, Language.FRENCH]
self._detector = LanguageDetectorBuilder.from_languages(*languages).build()
output = self._detector.detect_language_of(user_input)
if (output == Language.ENGLISH):
return 'en'
else:
return 'fr'
lang_detect = LangDetect.bind()Composing multiple models
Let’s bring the whole system together. We’ll implement a service which represents our external endpoint for HTTP or Python invocations.
- This service will have references to the deployments we’ve built so far, and will implement some conditional logic to ensure the correct language is used
- Note that even if the user is interacting in French, we need to return the English response as well so that client can use that to build the chat history
@serve.deployment
class Endpoint:
def __init__(self, chat, lang_detect, translate_en_fr, translate_fr_en):
# assign dependent service handles to instance variables
self._chat = chat
self._lang_detect = lang_detect
self._translate_en_fr = translate_en_fr
self._translate_fr_en = translate_fr_en
async def __call__(self, request: Request) -> dict:
data = await request.json()
data = json.loads(data)
return {'response': await self.get_response(data['user_input'], data['history']) }
async def get_response(self, user_input: str, history: list[str]):
lang_obj_ref = await self._lang_detect.get_response.remote(user_input)
# if we didn't need the literal value of the language yet, we could pass that (future) object reference to other services
# here, though, we need the value in order to decide whether to call the translation services
# we get the Python value by awaiting the object reference
lang = await lang_obj_ref
if (lang == 'fr'):
user_input = await self._translate_fr_en.get_response.remote(user_input)
response = response_en = await self._chat.get_response.remote(user_input, history)
if (lang == 'fr'):
response = await self._translate_en_fr.get_response.remote(response_en)
user_input = await user_input
response = await response
response_en = await response_en
return response + '|' + user_input + '|' + response_en
chat = Chat.bind(model='facebook/blenderbot-400M-distill')
endpoint = Endpoint.bind(chat, lang_detect, translate_en_fr, translate_fr_en)
endpoint_handle = serve.run(endpoint, name = 'multilingual_chat')We’ve implemented control flow through our services and used the async/await pattern in several places so that we don’t unnecessarily block.
Then we construct the service endpoint and start a new application serving that endpoint.
message = 'My friends are cool but they eat too many carbs.'
history = []
response = ray.get(endpoint_handle.get_response.remote(message, history))
response.split('|')[0]history += response.split('|')[1:]
historymessage = 'Je ne suis pas sûr.'
response = ray.get(endpoint_handle.get_response.remote(message, history))
response.split('|')[0]history += response.split('|')[1:]
historyAt this point we have a service which can support the many functional and operational properties we expect to need in production, including scalability, separation of concerns, and composability.
serve.delete('multilingual_chat')Lab activity: build a simpler translator
You can use Google’s Flan-T5 large model like this
from transformers import pipeline
pipe = pipeline("text2text-generation", model="google/flan-t5-large")This model can translate between English and several other languages if instructed to do so in the prompt.
Build a Serve application that
- detects in the input language
- translates (Engligh-Italian or the reverse) using Flan-T5
- returns the result