Ray-serve
Introduction to Ray Serve
Implement a simple service, understand key Ray Serve concepts like deployments, and observe a running Serve application.
import json
import ray
import requests
from ray import serve
from ray import tune
from ray.train import ScalingConfig, RunConfig
from ray.train.xgboost import XGBoostTrainer
from ray.tune import Tuner, TuneConfig
from starlette.requests import RequestRay Serve
Roadmap to Serve introduction
- See Serve in the context of Ray AI libraries
- Implement a simple service
- Understand key concepts of Ray Serve including deployments
- Observe a running Serve application
Context: Ray libraries
Ray includes set of high-level easy-to-use APIs for ingesting data, training models – including reinforcement learning models – tuning those models and then serving them.
Key principles behind Ray and its libraires are
- Performance
- Developer experience and simplicity
Read, preprocess with Ray Data
dataset = ray.data.read_parquet("s3://anonymous@anyscale-training-data/intro-to-ray-air/nyc_taxi_2021.parquet").repartition(16)
train_dataset, valid_dataset = dataset.train_test_split(test_size=0.3)Fit model with Ray Train
trainer = XGBoostTrainer(
label_column="is_big_tip",
scaling_config=ScalingConfig(num_workers=4, use_gpu=False),
params={ "objective": "binary:logistic", },
datasets={"train": train_dataset, "valid": valid_dataset},
run_config=RunConfig(storage_path='/mnt/cluster_storage/')
)
result = trainer.fit()Optimize hyperparams with Ray Tune
tuner = Tuner(trainer,
param_space={'params' : {'max_depth': tune.randint(2, 12)}},
tune_config=TuneConfig(num_samples=3, metric='train-logloss', mode='min'),
run_config=RunConfig(storage_path='/mnt/cluster_storage/'))
checkpoint = tuner.fit().get_best_result().checkpointBatch prediction
class OfflinePredictor:
def __init__(self):
import xgboost
self._model = xgboost.Booster()
self._model.load_model(checkpoint.path + '/model.json')
def __call__(self, batch):
import xgboost
import pandas as pd
dmatrix = xgboost.DMatrix(pd.DataFrame(batch))
outputs = self._model.predict(dmatrix)
return {"prediction": outputs}predicted_probabilities = valid_dataset.drop_columns(['is_big_tip']).map_batches(OfflinePredictor, compute=ray.data.ActorPoolStrategy(size=2))predicted_probabilities.take_batch()Online prediction with Ray Serve
@serve.deployment
class OnlinePredictor:
def __init__(self, checkpoint):
import xgboost
self._model = xgboost.Booster()
self._model.load_model(checkpoint.path + '/model.json')
async def __call__(self, request: Request) -> dict:
data = await request.json()
data = json.loads(data)
return {"prediction": self.get_response(data) }
def get_response(self, data):
import xgboost
import pandas as pd
dmatrix = xgboost.DMatrix(pd.DataFrame(data, index=[0]))
return self._model.predict(dmatrix)
handle = serve.run(OnlinePredictor.bind(checkpoint=checkpoint))sample_input = valid_dataset.take(1)[0]
del(sample_input['is_big_tip'])
del(sample_input['__index_level_0__'])
requests.post("http://localhost:8000/", json=json.dumps(sample_input)).json()serve.shutdown()Ray Serve
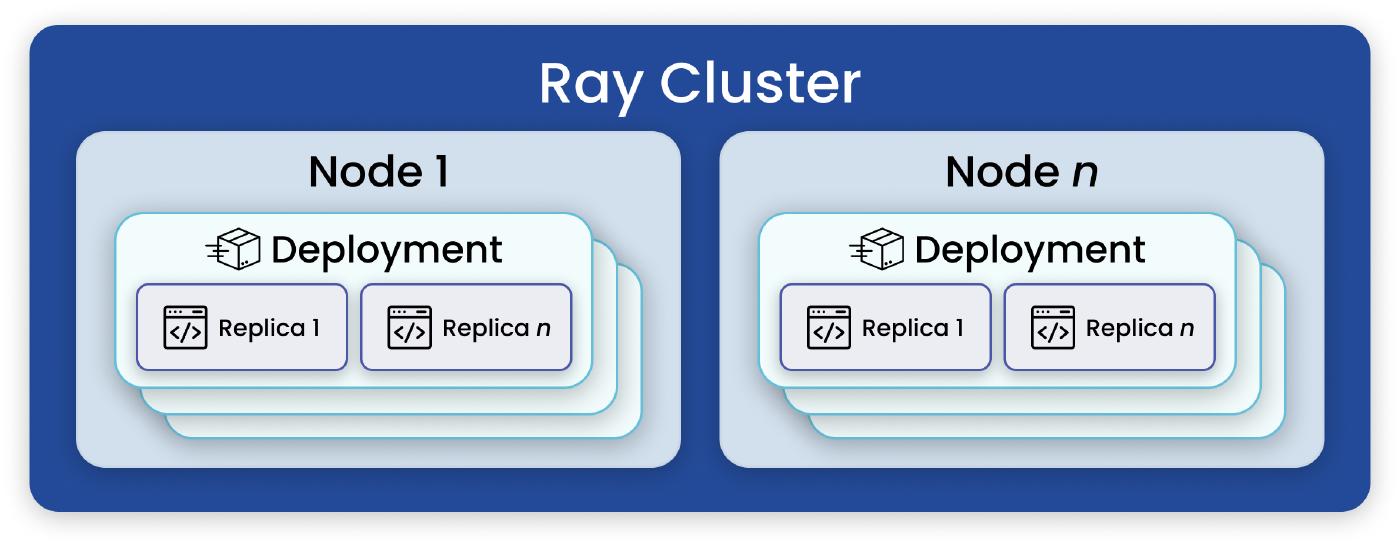
Serve is a framework for serving ML applications
Deployments
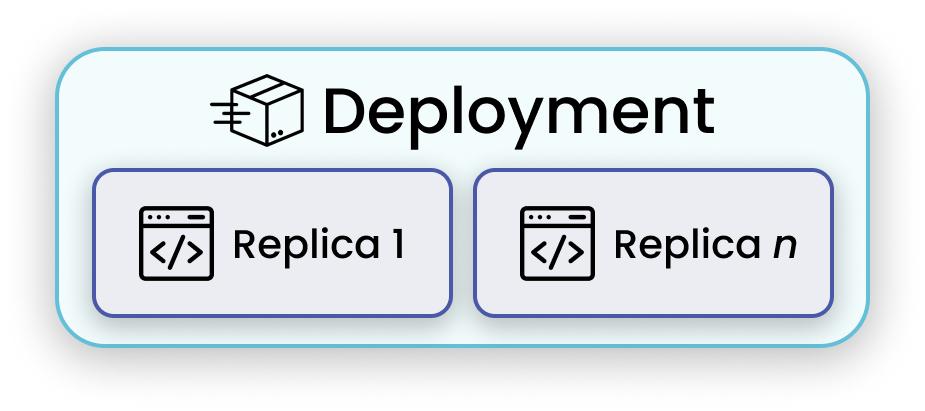
Deployment is the fundamental user-facing element of serve.
Roadmap to initial chat app on serve
- Discover serve deployments via Hello World example
- Replace placeholder “Hello World” logic with Huggingface transformers chatbot
- Reserve GPU resources for our chatbot service
Our First Service
Let’s jump right in and get something simple up and running on Ray Serve.
@serve.deployment
class Chat:
def __init__(self, msg: str):
self._msg = msg # initial state
async def __call__(self, request: Request) -> dict:
data = await request.json()
data = json.loads(data)
return {"result": self.get_response(data['input']) }
def get_response(self, message: str) -> str:
return self._msg + message
handle = serve.run(Chat.bind(msg="Yes... "), name='hello_world')We can test it as an HTTP endpoint
sample_json = '{ "input" : "hello" }'
requests.post("http://localhost:8000/", json = sample_json).json()Lab activity: implement a web service with Ray Serve
The following function will calculate the approximate loan payment for a car.
def monthly_payment(total_price, rate, years_of_loan):
n = 365.25 # compounding periods
total_paid = total_price * (((1 + ((rate/100.0)/n)) ** (n*years_of_loan)))
per_month = total_paid / (12 * years_of_loan)
return per_monthKey APIs and concepts
Using Ray Serve, a single Ray cluster can host multiple applications
Applications are coarse-grained chunks of functionality which can be independently upgraded (i.e., without impacting other applications on the same cluster)
An application is made up of one or more deployments
A deployment is a smaller component which can
- specify its own hardware are other resource requirements (like GPUs)
- specify its own runtime environments (like libraries)
- scale independently (including autoscaling)
- maintain state (e.g., models)
We can use deployments to achieve separation of concerns – e.g., separating different models, chunks of business logic, or data conversion
Ingress deployments are typically accessed via HTTP, while other supporting deployments are typically accessed at runtime via a Python ServeHandle – allowing any Serve component (or Ray code) to interact directly with other components as needed
We create a deployment by applying the @serve.deployment decorator to a regular Python class or function. We create and start an application by calling serve.run on a deployment (typically an ingress deployment).
Demo: calling a component from Python via a ServeHandle
response = handle.get_response.remote('hello')
responseIn order to support maximal performance, values from remote calls, such as our response string here, are returned as object references (a bit like futures or promises in some frameworks). If we want to block, wait for the result to be ready, and retrieve it, we can use ray.get(...)
ray.get(response)Demo: observing application and deployment status
! serve statusserve.status()Check the Ray dashboard as well to see more information
serve.delete('hello_world')